Now that we have prepared our environment and loaded base data and started to understand the data, let's turn our focus to engineering some new features.
Engineer Data
We'll start by engineering new featured derived from our base data, and then fold in a couple of external data sources. In particular, let's build some features that describe some geographic properties about the areas where each fire began. Two factors integral to the occurrence of a wildfire, but that are only loosely captured in our base data, are land cover and human behavior.
Land Cover plays a role in wildfire creation for a number of reasons. Vegetation can be more or less flammable depending on the time of year - coniferous forests can become especially flagrant during a hot dry summer. Certain land cover classes lend themselves to different activities - forestry won't be prevalent in grasslands. To capture this in our model, we'll engineer a new feature that describes the land cover in the area surrounding each fire. We'll base the feature on Multi Resolution Land Cover, and use a binning strategy to aggregate our base points geographically.
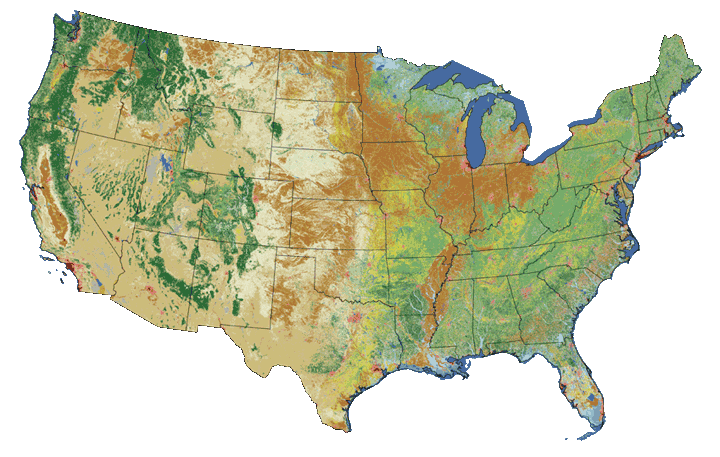
Land cover classes from the National Land Cover Database.
Human behavior also plays a large role in the occurrence of wildfires. As we saw during EDA, over 40% of wildfires occur as a result of Debris Burning or Arson -- both human behaviors. While a rough measure at best, the presence of humans and dwellings may correlate with the cause of wildfires - particularly those of human origin. We can use US Census Grid, employing a similar binning strategy as above, to engineer a couple of features around humans in the areas around wildfires.

Both of the above engineering tasks require binning. Originally, I had intended to use a geohash binning technique. At that point of the project, we were still looking at data from Alaska. Unfortunately at those latitudes, geohash becomes quite distorted. To mitigate distortion in our bins, I switched to Uber's H3 binning system.

A compact representation of California using Uber's H3 binning tool.
H3 provides tools to generate an H3 bin from a set of coordinates, and a boundary shape for an H3 bin. In conjunction, these functions allow us to assign a bin to each wildfire, and then use that bin's geography to extract geodata from the raster datasets.
In any case, let's dive in.
Quantify Data
A couple fields in our reduced set are still non-numeric, in particular the STATE field is categorical text - let's convert this to a numeric label using sklearn.preprocessing.LabelEncoder.
label_encoder = sklearn.preprocessing.LabelEncoder()
for key, dataframe in fires_df.items():
fires_df[key].loc[:,'STATE_CODE'] = label_encoder.fit_transform(dataframe['STATE'])STAT_CAUSE_CODE is not zero-inded - let's use our label encoder to add a new set of labels
label_encoder = sklearn.preprocessing.LabelEncoder()
for key, dataframe in fires_df.items():
fires_df[key].loc[:,'STAT_CAUSE_CODE_ZERO'] = label_encoder.fit_transform(dataframe['STAT_CAUSE_CODE'])Missing Data
None of the fields that we're concerned with have missing data. We'll skip this for now.
Discovery Week of Year
Let's create a feature that reduces the resolution of DISCOVERY_DOY
for key, dataframe in fires_df.items():
dataframe['DISCOVERY_WEEK'] = dataframe['DISCOVERY_DOY']\
.apply(lambda x: math.floor(x/7) + 1)Climate Regions
Let's create a feature that abstracts the STATE column already in our data. We'll use NOAA's U.S. Climate Regions to group states into larger units that share certain environmental characteristics.
climate_regions = {
"northwest": ["WA","OR","ID"],
"west": ["CA","NV"],
"southwest": ["UT","CO","AZ","NM"],
"northern_rockies": ["MT","ND","SD","WY","NE"],
"upper_midwest": ["KS","OK","TX","AR","LA","MS"],
"south": ["MN","WI","MI","IA"],
"ohio_valley": ["MO","IL","IN","OH","WV","KY","TN"],
"southeast": ["VA","NC","SC","GA","AL","FL"],
"northeast": ["ME","NH","VT","NY","PA","MA","RI","CT","NJ","DE","MD","DC"],
"alaska": ["AK",],
"hawaii": ["HI"],
"puerto_rico": ["PR"]
}
state_region_mapping = {}
for region, region_states in climate_regions.items():
for state in region_states:
state_region_mapping[state] = region
for key, dataframe in fires_df.items():
dataframe['CLIMATE_REGION'] = dataframe['STATE']\
.apply(lambda x: state_region_mapping[x])
label_encoder = sklearn.preprocessing.LabelEncoder()
for key, dataframe in fires_df.items():
dataframe['CLIMATE_REGION_CODE'] = label_encoder.fit_transform(dataframe['CLIMATE_REGION'])H3 Bins
In preparation to extract data from geo rasters, or perform other geoanalysis, let's bin our wildfires using uber/h3. Binning helps mitigate variable resolution of source data, reduce computational complexity of feature engineering, and hopefully help avoid overfitting.
Since there are no python bindings for H3 - although they are forthcoming - I took the approach of calling the H3 binaries using python's subprocess. This works fairly well, especially when calls are batched.
Calcluate Bins for fires_df
Start by calculating a bin for each wildfire using geoToH3. We do this batched to improve performance. We're using resolution 5.
def h3_for_chunk(chunk, precision):
lat_lon_lines = "\n".join([
"{} {}".format(row['LATITUDE'], row['LONGITUDE']) for index,row in chunk.iterrows()
])
h3 = subprocess.run(
['/tools/h3/bin/geoToH3', str(precision)],
input=str.encode(lat_lon_lines),
stdout=subprocess.PIPE).stdout.decode('utf-8').splitlines()
return pd.DataFrame({
"H3": h3
}, index=chunk.index)
def chunker(seq, size):
return (seq.iloc[pos:pos + size] for pos in range(0, len(seq), size))
for key in fires_df:
print('Calculating bins for fires_df["{}"]'.format(key))
h3_df = pd.DataFrame()
with tqdm_notebook(total=fires_df[key].shape[0]) as pbar:
for chunk in chunker(fires_df[key], 10000):
h3_df = h3_df.append(h3_for_chunk(chunk, 5))
pbar.update(chunk.shape[0])
fires_df[key].drop('H3', 1, inplace=True, errors='ignore')
fires_df[key] = fires_df[key].merge(
h3_df,
how='left',
left_index=True,
right_index=True,
copy=False
)
display(fires_df[key].sample(5))Calculating bins for fires_df["train"]Calculating bins for fires_df["test"]Isolate Bins
Identify unique bins in the wildfires dataframe and create a new GeoDataFrame, bins, containing only the bins. GeoDataFrame comes from the GeoPandas project that adds a layer of geographic processing on top of Pandas. For our use, we're most concerned with the ability to store, and plot geographic shapes. Under the covers, GeoPandas uses the Shapely library for geometric analysis.
bins = gpd.GeoDataFrame({
'H3': np.unique(np.concatenate((fires_df["train"].H3.unique(), fires_df["test"].H3.unique())))
})
print(bins.info())
bins.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 25999 entries, 0 to 25998
Data columns (total 1 columns):
H3 25999 non-null object
dtypes: object(1)
memory usage: 203.2+ KB
NoneCalculate Bounds
Calculate bounds for each bin in bins. This should batched as well - it takes quite a while to run.
def h3_bounds_for_bin(h3_bin):
h3_bounds = subprocess.run(
['/tools/h3/bin/h3ToGeoBoundary'],
input=str.encode(h3_bin),
stdout=subprocess.PIPE).stdout.decode('utf-8').splitlines()
coords = []
for coord in h3_bounds[2:-1]:
lon_lat = coord.lstrip().split(" ")
coords.append(((float(lon_lat[1]) - 360.), float(lon_lat[0])))
return shapely.geometry.Polygon(coords)
bins['GEOMETRY'] = bins['H3'].apply(h3_bounds_for_bin)
print(bins.info())
bins.sample(10)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 2 columns):
H3 27099 non-null object
GEOMETRY 27099 non-null object
dtypes: object(2)
memory usage: 423.5+ KB
NoneNow we have a geodataframe, bins, that contains all of the bins whose geography contains at least one wildfire.
Land Cover Classification

As discussed above, land cover has a direct effect in the occurrence of wildfires. In order to incorporate land cover into our model, we'll engineer a feature based on DOI & USGS's Multiple Resolution Land Cover National Land Cover Database 2011. The data comes in a raster format with a 30 meter resolution. Each pixel can be one of the 20 classes described in the table to the right. A Land Use And Land Cover Classification System For Use With Remote Sensor Data provides some interesting context for land cover classification.
We'll use Mapbox's rasterio and rasterstats to extract land cover data about each of our bins. That data will come as a dict containing a count of points for each land cover class. We'll transform that data into a format more useful for our model.
The fact that we're using land cover data from 2011 alone threatens the value of this feature. While annual land cover data is not available, there is data available from 2001, and 2006. An improvement would be to select data from each of the three sets, 2001, 2006, or 2011, as appropriate.
We'll start by making a copy of our bins dataframe so that we can experiment without trashing upstream work.
bins_land_cover = bins.copy()Let's define the path to our data file.
land_cover_path = "/data/188-million-us-wildfires/src/nlcd_2011_landcover_2011_edition_2014_10_10/nlcd_2011_landcover_2011_edition_2014_10_10.img"Define Coordinate Transformation
Before we use rasterstats to count the values in each bin, we use pyproj to reproject project our bin's geometry into the CRS of our datasource.
project = functools.partial(
pyproj.transform,
pyproj.Proj(init='EPSG:4326'),
pyproj.Proj('+proj=aea +lat_1=29.5 +lat_2=45.5 +lat_0=23 +lon_0=-96 +x_0=0 +y_0=0 +ellps=GRS80 +datum=NAD83 +units=m +no_defs'))Raster Samples
Before we extract information from our source raster, let's preview the contents to sanity check.
land_cover_data = rasterio.open(land_cover_path)
def render_masked_bin(row):
return rasterio.mask.mask(
land_cover_data,
[shapely.geometry.mapping(transform(project, row['GEOMETRY']))],
crop=True
)
masked_bin_images = bins_land_cover.sample(6).apply(render_masked_bin, 1).tolist()
fig, plots = plt.subplots(3, 2)
for index, val in enumerate(masked_bin_images):
my_plot = plots[math.floor(index/2)][index % 2]
rasterio.plot.show(val[0], ax=my_plot, transform=val[1], cmap='gist_earth')
my_plot.axis('on')

Calculate Land Cover
Now that we've confirmed that the data we're masking from our source raster looks reasonable, let's get to extracting it. Let's employ zonal_stats with categorial=True - this will returns out dict of counts for each value found in the masked region.
land_cover_path = "/data/188-million-us-wildfires/src/nlcd_2011_landcover_2011_edition_2014_10_10/nlcd_2011_landcover_2011_edition_2014_10_10.img"
def land_cover_for_geometry(geometry):
stats = zonal_stats(
[shapely.geometry.mapping(transform(project, geometry))],
land_cover_path,
nodata=-999,
categorical=True
)
return stats[0]
bins_land_cover = bins.copy()
bins_land_cover["LAND_COVER"] = bins_land_cover["GEOMETRY"].apply(land_cover_for_geometry)
print(bins_land_cover.info())
bins_land_cover.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 3 columns):
H3 27099 non-null object
LAND_COVER 27099 non-null object
GEOMETRY 27099 non-null object
dtypes: object(3)
memory usage: 635.2+ KB
NoneCalculate Primary Class
Let's create a feature describing the primary land cover level II class for each bin.
def primary_land_cover(land_cover):
return max(land_cover, key=land_cover.get)
bins_land_cover["PRIMARY_LAND_COVER"] = bins_land_cover["LAND_COVER"].apply(primary_land_cover)
print(bins_land_cover.info())
bins_land_cover.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 4 columns):
H3 27099 non-null object
LAND_COVER 27099 non-null object
GEOMETRY 27099 non-null object
PRIMARY_LAND_COVER 27099 non-null object
dtypes: object(4)
memory usage: 846.9+ KB
NoneCategorize Primary Class
Let's group each bin's primary land cover class into it's Level I class.
land_cover_categories = {
"water": [11, 12],
"developed": [21, 22, 23, 24],
"barren": [31],
"forest": [41, 42, 43],
"shrubland": [51, 52],
"herbaceous": [71, 72, 73, 74],
"planted_cultivated": [81, 82],
"wetlands": [90, 95]
}
land_cover_categories_map = {}
for category, values in land_cover_categories.items():
for value in values:
land_cover_categories_map[value] = category
def land_cover_category_for_class(land_cover_class):
return land_cover_categories_map[int(land_cover_class)] if int(land_cover_class) in land_cover_categories_map else 'unknown'
bins_land_cover["PRIMARY_LAND_COVER_CATEGORY"] = bins_land_cover["PRIMARY_LAND_COVER"].apply(land_cover_category_for_class)
print(bins_land_cover.info())
bins_land_cover.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 5 columns):
H3 27099 non-null object
LAND_COVER 27099 non-null object
GEOMETRY 27099 non-null object
PRIMARY_LAND_COVER 27099 non-null object
PRIMARY_LAND_COVER_CATEGORY 27099 non-null object
dtypes: object(5)
memory usage: 1.0+ MB
NoneEncode
Employ LabelEncoder to assign a numeric value to each category.
for key, dataframe in fires_df.items():
label_encoder = sklearn.preprocessing.LabelEncoder()
bins_land_cover.loc[:,'PRIMARY_LAND_COVER_CODE'] = label_encoder.fit_transform(bins_land_cover['PRIMARY_LAND_COVER'])
label_encoder = sklearn.preprocessing.LabelEncoder()
bins_land_cover.loc[:,'PRIMARY_LAND_COVER_CATEGORY_CODE'] = label_encoder.fit_transform(bins_land_cover['PRIMARY_LAND_COVER_CATEGORY'])
print(bins_land_cover.info())
bins_land_cover.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 7 columns):
H3 27099 non-null object
LAND_COVER 27099 non-null object
GEOMETRY 27099 non-null object
PRIMARY_LAND_COVER 27099 non-null object
PRIMARY_LAND_COVER_CATEGORY 27099 non-null object
PRIMARY_LAND_COVER_CODE 27099 non-null int64
PRIMARY_LAND_COVER_CATEGORY_CODE 27099 non-null int64
dtypes: int64(2), object(5)
memory usage: 1.4+ MB
NoneLand Cover Percentage
After all the above categorizing, let's make some continuous values. We'll create a new column for each land cover class in each bin that describes how much of that bin is covered by that class. Since we'll have some null values in the resulting dataset, let's make sure to set those to 0.
drop_cols = [c for c in bins_land_cover.columns if c[:15] == "LAND_COVER_PCT_"]
bins_land_cover = bins_land_cover.drop(drop_cols, 1)
def land_cover_percentages(row):
total = 0
for lc_class, val in row['LAND_COVER'].items():
total = total + int(val)
output = {}
for lc_class, val in row['LAND_COVER'].items():
pct = val / total
row['LAND_COVER_PCT_{}'.format(lc_class)] = pct
return row
bins_land_cover = bins_land_cover.apply(land_cover_percentages, 1)
bins_land_cover.loc[
:,[c for c in bins_land_cover.columns if c[:15] == "LAND_COVER_PCT_"]
] = bins_land_cover[[c for c in bins_land_cover.columns if c[:15] == "LAND_COVER_PCT_"]].fillna(0)
print(bins_land_cover.info())
bins_land_cover.sample(5)<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 7 columns):
H3 27099 non-null object
LAND_COVER 27099 non-null object
PRIMARY_LAND_COVER 27099 non-null object
PRIMARY_LAND_COVER_CATEGORY 27099 non-null object
PRIMARY_LAND_COVER_CATEGORY_CODE 27099 non-null int64
PRIMARY_LAND_COVER_CODE 27099 non-null int64
GEOMETRY 27099 non-null object
dtypes: int64(2), object(5)
memory usage: 1.4+ MB
NoneMerge onto fires_df
Merge our bins_land_cover onto our wildfire data keying on the H3 bin column.
for key, dataframe in fires_df.items():
fires_df[key] = dataframe.merge(bins_land_cover, on="H3", how="left")
display(fires_df[key].sample(5))5 rows × 22 columns
5 rows × 22 columns
Alas, we now have a handful of features related to Land Cover on our main dataframe. Let's move onto some other features!
Census Data
In addition to land cover, human behavior plays a large role the the creation of wildfires. Similarly to how we engineered features around Land Cover, we can bring in an external dataset to engineer some features around population and human behavior. Fortunately, it's possible to obtain 2010 US Census Data in a raster format allowing us to employ the the same techniques that we did for land cover.
US Census publishes a number of interesting metrics: for our purposes, we will look at Population Density, Seasonal Housing, Housing Units, and Occupied Housing Units. For each of these, we will look at the mean value for each bin.
Similarly to the Land Cover data, this method is flawed in it's use of data from 2010. Since the wildfires we're looking at occurred in the years 1995-2015, 2010 census data may not be highly relevant to some of the earlier or later datapoints.
As with Land Cover, start by creating a new dataframe to house or work with the census data.
census_data = pd.DataFrame(
{"H3": bins['H3'].copy()},
index=bins.index
)Raster Samples
Before we extract information from our source raster, let's preview the contents to sanity check.
census_files = {
"Population Density": "/data/188-million-us-wildfires/src/usgrid_data_2010/uspop10.tif",
"Seasonal Housing": "/data/188-million-us-wildfires/src/usgrid_data_2010/ussea10.tif",
"Housing Units": "/data/188-million-us-wildfires/src/usgrid_data_2010/ushu10.tif",
"Occupied Housing Units": "/data/188-million-us-wildfires/src/usgrid_data_2010/usocc10.tif"
}
def render_bin(row):
output = []
for index, value in census_files.items():
census_data = rasterio.open(value)
output.append(rasterio.mask.mask(
census_data,
[shapely.geometry.mapping(row['GEOMETRY'])],
crop=True,
nodata=0
))
return output
masked_bin_images = bins_land_cover.sample(2).apply(render_bin, 1).tolist()
fig, plots = plt.subplots(4, 2)
for index, val in enumerate(masked_bin_images):
for subindex, image in enumerate(val):
my_plot = plots[subindex][index]
rasterio.plot.show(image[0], ax=my_plot, transform=image[1], cmap='inferno')

Looks reasonable, let's create our features!
Population Density
Start with Population Density, use zonal_stats to extract the mean value for each bin. Add the values as a new column to our dataframe.
census_population_path = "/data/188-million-us-wildfires/src/usgrid_data_2010/uspop10.tif"
def mean_population_density_for_geometry(geometry):
stats = zonal_stats(
[shapely.geometry.mapping(geometry)],
census_population_path,
nodata=0,
stats=["mean"]
)
return stats[0]["mean"]
census_data = census_data.drop("MEAN_POPULATION_DENSITY", 1, errors='ignore')
census_data["MEAN_POPULATION_DENSITY"] = \
bins["GEOMETRY"].apply(mean_population_density_for_geometry).fillna(value=0).replace([-np.inf], 0)
print(census_data.info())
census_data.sample(5)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 2 columns):
H3 27099 non-null object
MEAN_POPULATION_DENSITY 27099 non-null float64
dtypes: float64(1), object(1)
memory usage: 423.5+ KB
NoneSeasonal Housing
census_seasonal_path = "/data/188-million-us-wildfires/src/usgrid_data_2010/ussea10.tif"
def mean_seasonal_housing_for_geometry(geometry):
stats = zonal_stats(
[shapely.geometry.mapping(geometry)],
census_seasonal_path,
nodata=0,
stats=["mean"]
)
return stats[0]["mean"]
census_data = census_data.drop("MEAN_SEASONAL_HOUSING", 1, errors='ignore')
census_data["MEAN_SEASONAL_HOUSING"] = \
bins["GEOMETRY"].apply(mean_seasonal_housing_for_geometry).fillna(value=0).replace([-np.inf], 0)
print(census_data.info())
census_data.sample(5)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 3 columns):
H3 27099 non-null object
MEAN_POPULATION_DENSITY 27099 non-null float64
MEAN_SEASONAL_HOUSING 27099 non-null float64
dtypes: float64(2), object(1)
memory usage: 635.2+ KB
NoneHousing Units
census_housing_units = "/data/188-million-us-wildfires/src/usgrid_data_2010/ushu10.tif"
def mean_housing_units_for_geometry(geometry):
stats = zonal_stats(
[shapely.geometry.mapping(geometry)],
census_housing_units,
nodata=0,
stats=["mean"]
)
return stats[0]["mean"]
census_data = census_data.drop("MEAN_HOUSING_UNITS", 1, errors='ignore')
census_data["MEAN_HOUSING_UNITS"] = \
bins["GEOMETRY"].apply(mean_housing_units_for_geometry).fillna(value=0).replace([-np.inf], 0)
print(census_data.info())
census_data.sample(5)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 4 columns):
H3 27099 non-null object
MEAN_POPULATION_DENSITY 27099 non-null float64
MEAN_SEASONAL_HOUSING 27099 non-null float64
MEAN_HOUSING_UNITS 27099 non-null float64
dtypes: float64(3), object(1)
memory usage: 846.9+ KB
NoneOccupied Housing Units
census_occupied_housing_units = "/data/188-million-us-wildfires/src/usgrid_data_2010/usocc10.tif"
def mean_occupied_housing_units_for_geometry(geometry):
stats = zonal_stats(
[shapely.geometry.mapping(geometry)],
census_occupied_housing_units,
nodata=0,
stats=["mean"]
)
return stats[0]["mean"]
census_data = census_data.drop("MEAN_OCCUPIED_HOUSING_UNITS", 1, errors='ignore')
census_data["MEAN_OCCUPIED_HOUSING_UNITS"] = \
bins["GEOMETRY"]\
.apply(mean_occupied_housing_units_for_geometry)\
.fillna(value=0)\
.replace([-np.inf], 0)
print(census_data.info())
census_data.sample(5)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27099 entries, 0 to 27098
Data columns (total 5 columns):
H3 27099 non-null object
MEAN_POPULATION_DENSITY 27099 non-null float64
MEAN_SEASONAL_HOUSING 27099 non-null float64
MEAN_HOUSING_UNITS 27099 non-null float64
MEAN_OCCUPIED_HOUSING_UNITS 27099 non-null float64
dtypes: float64(4), object(1)
memory usage: 1.0+ MB
NoneVacant Housing Units
Let's compare overall Housing Units and Occupied Housing Units to create a feature around vacant housing units.
census_data["MEAN_VACANT_HOUSING_UNITS"] = census_data["MEAN_HOUSING_UNITS"] - census_data["MEAN_OCCUPIED_HOUSING_UNITS"]Merge onto fires_df
Let's merge our Census features onto our main data frame.
for key, dataframe in fires_df.items():
fires_df[key] = fires_df[key]\
.drop([
"MEAN_POPULATION_DENSITY",
"MEAN_SEASONAL_HOUSING",
"MEAN_HOUSING_UNITS",
"MEAN_OCCUPIED_HOUSING_UNITS",
"MEAN_VACANT_HOUSING_UNITS"
], axis=1, errors='ignore')
fires_df[key] = dataframe.merge(census_data, on="H3", how="left")
display(fires_df[key].sample(5))5 rows × 27 columns
5 rows × 27 columns
Conclusion
Well that's all for now. In this blog post we engineered a handful of features both using data already present in our base dataset, and by incorporating new datasets. We geographically binned our datapoints, and used the geometry of each bin to extract statistics from land cover and human behavior raster files.
There is a lot that can be done to improve this - if you think there's something that could be approached differently, I want to hear from you! Please reach out: andrewmahon@fastmail.com.
Next post we'll revisit our Exploratory Data Analysis with a focus on our new features.
Updates
2017/2/14 - initial post 2017/2/22 - fixed a couple of typos